
Dr.-Ing. Norbert Oster
Wissenschaftliche Mitarbeitende
Adresse
Kontakt
Laufende Projekte
Automatische Bewertung von Java- und Scala-Hausaufgaben
(Projekt aus Eigenmitteln)Project leader: ,
Term: 18.07.2013 - 30.11.2028
Acronym: AuDoscore/ScExFuSS
URL: https://www.ps.tf.fau.de/forschung/forschungsprojekte/audoscore-scexfuss/Viele Studierende üben früh objekt-orientierte oder funktionale Programmierung durch das selbständige Implementieren von Hausaufgaben. Die immensen Teilnehmerzahlen und divergierenden Lösungsansätze erschweren es Dozierenden, die Hausaufgaben (oft Prüfungsleistungen) nach einem einheitlichen Maßstab zu bewerten.
Deshalb haben wir 2013 (damals auf Basis von Java-1.7, JUnit-4 und Scala-2.12) eine Erweiterung von JUnit entwickelt, deren Quellen wir unter https://github.com/FAU-Inf2/AuDoscore (Java) bzw. https://github.com/FAU-Inf2/ScExFuSS (Scala) veröffentlichen. Annotationen versehen Testfälle mit einer Bonus- oder Malus-Wertung. Die Ergebnisse der Testausführung werden erfasst und daraus vollautomatisch eine Gesamtpunktzahl errechnet. Die Bewertung erfolgt dabei in vier Stufen, wobei jede ggf. sofort ein ausführliches Feedback liefert.
Im Jahr 2025 haben wir AuDoscore und ScExFuSS umfassend überarbeitet, nachdem zentrale Komponenten wegen der abrupten Evolution von Java, JUnit und Scala nicht mehr durch stetige Anpassungen lauffähig waren. Seit Java-25 ist der SecurityManager als Sicherheitsinfrastruktur deaktiviert. Durch die starke Einschränkung der Java-Compiler-API wurde sie für unsere Zwecke unbrauchbar. Wegen der syntaktischen Änderungen am Quell- und Byte-Code wurde die bisherige musterbasierte Problemerkennung nicht-deterministisch. Neuere JUnit-Versionen haben grundlegend andere (zu den alten inkompatible) Erweiterungsmechanismen.
Daraus ergaben sich u.a. folgende Fragen:
- Wie sicher verhindern, dass Studierende (un)absichtlich das Bewertungssystem selbst stören (bislang durch SecurityManager)?
- Wie erkennen, wenn Studierende explizit verbotene API-Funktionen nutzen (deklarierte @Forbidden/@NotForbidden-Annotationen)?
- Wie bei der Bewertung berücksichtigen, dass Studierende aufeinander aufbauende Funktionen fehlerhaft implementieren (Folgefehler)?
- Wie AuDoscore und ScExFuSS in die neueste JUnit-Infrastruktur integrieren?
Zur Lösung in AuDoscore nutzen wir nunmehr das "Classfile-Package" aus der Java-25-API. Als Ersatz für den SecurityManager und zur Umsetzung der "@[Not]Forbidden"-Annotationen untersuchen wir damit direkt den Bytecode nach gefährlichen oder verbotenen Funktionsaufrufen. Zur Umgehung von Folgefehlern transplantieren wir damit Klassen, Methoden oder Felder aus dem Bytecode der Musterlösung in die studentische. Dabei sind viele schwierige Sonderfälle (z.B. wegen "Type Erasure", "Lambdas" u.v.m.) zu behandeln, wozu wir ggf. auch Teile des Bytecodes transferieren, die nicht unmittelbar im Code-Block der zu ersetzenden Methode stehen und übersetzen die Tests für jeden Testfall passend neu.
Zur Lösung in ScExFuSS verwenden wir aktuell die vom Compiler erzeugen TASTy-Dateien (Typed Abstract Syntax Trees) mittels des "Scala-3 Tasty-Inspectors". Als Ersatz für den SecurityManager und zur Behandlung der "@[Not]Forbidden"-Annotationen prüfen wir statisch, welche Funktionen tatsächlich verwendet werden. Die Folgefehler-Funktion auf Basis der TASTy-Dateien ist nun erstmals auch für Scala verfügbar.
Zwecks Migration zu JUnit-6 haben wir AuDoscore, ScExFuSS und alle Tests auf JUnit-Jupiter portiert. Das "Einklinken" in den gesamten Prozess der Testausführung und das Protokollieren der Bewertungsereignisse wurde dazu von Grund auf neu implementiert. Infolge dessen haben wir auch alle vorhandenen Selbsttests aktualisiert und weitere ergänzt, um sicherzustellen, dass alle Änderungen und auch alle neuen Sprachmittel von Java-25, Scala-3 und JUnit-6 korrekt behandelt werden.
Abgeschlossene Projekte
Verifikation und Validierung in der industriellen Praxis
(Projekt aus Eigenmitteln)Project leader:
Term: 01.01.2022 - 31.12.2024
Acronym: V&ViP
URL: https://www.ps.tf.fau.de/forschung/forschungsprojekte/vvip/Informatik als Grundlage eines erfolgreichen MINT-Studiums entlang der Bildungskette fördern
(Drittmittelfinanzierte Einzelförderung)Project leader: , ,
Term: 01.11.2019 - 31.10.2022
Acronym: CS4MINTS
Funding source: Bayerisches Staatsministerium für Wissenschaft und Kunst (StMWK) (seit 2018)
URL: https://www.ddi.tf.fau.de/forschung/laufende-projekte/cs4mints-informatik-als-grundlage-eines-erfolgreichen-mint-studiums-entlanGrundlagen der Informatik als Fundament eines zukunftsorientierten MINT-Studiums
(Drittmittelfinanzierte Einzelförderung)Project leader: , ,
Term: 01.10.2016 - 30.09.2019
Acronym: GIFzuMINTS
Funding source: Bayerisches Staatsministerium für Bildung und Kultus, Wissenschaft und Kunst (ab 10/2013)
URL: https://www.ps.tf.fau.de/forschung/forschungsprojekte/#gifzumintsMethoden und Werkzeuge zur iterativen Entwicklung und Optimierung von Software für eingebettete Multicore-Systeme
(Drittmittelfinanzierte Einzelförderung)Project leader:
Term: 15.10.2012 - 30.11.2014
Acronym: WEMUCS
Funding source: Bayerisches Staatsministerium für Wirtschaft, Infrastruktur, Verkehr und Technologie (StMWIVT) (bis 09/2013)
URL: https://www.ps.tf.fau.de/forschung/forschungsprojekte/#wemucsInter-Thread Testing
(Projekt aus Eigenmitteln)Project leader:
Term: 01.01.2012 - 31.12.2013
Acronym: InThreaTAutomatische Testdatengenerierung zur Unterstützung inkrementeller modell- und codebasierter Testprozesse für hochzuverlässige Softwaresysteme
(Drittmittelfinanzierte Einzelförderung)Project leader:
Term: 01.03.2006 - 31.10.2009
Acronym: UnITeD
Funding source: Bayerisches Staatsministerium für Wirtschaft, Infrastruktur, Verkehr und Technologie (StMWIVT) (bis 09/2013)
Testen von Softwaresystemen
Grunddaten
| Titel | Testen von Softwaresystemen |
|---|---|
| Kurztext | TSWS |
| Turnus des Angebots | nur im Sommersemester |
| Semesterwochenstunden | 4 |
Parallelgruppen / Termine
1. Parallelgruppe
| Semesterwochenstunden | 4 |
|---|---|
| Lehrsprache | Deutsch |
| Verantwortliche/-r |
Jonas Butz Dr.-Ing. Norbert Oster |
| Zeitpunkt | Startdatum - Enddatum | Ausfalltermin | Durchführende/-r | Bemerkung | Raum |
|---|---|---|---|---|---|
| wöchentlich Mi, 16:15 - 17:45 | 15.04.2026 - 15.07.2026 |
|
11301.00.005 | ||
| wöchentlich Do, 16:15 - 17:45 | 16.04.2026 - 16.07.2026 | 04.06.2026 14.05.2026 |
|
12801.01.220 |
Intensivübungen zu Parallele und Funktionale Programmierung
Grunddaten
| Titel | Intensivübungen zu Parallele und Funktionale Programmierung |
|---|---|
| Kurztext | PFP-IÜ |
| Turnus des Angebots | nur im Sommersemester |
| Semesterwochenstunden | 2 |
Parallelgruppen / Termine
1. Parallelgruppe
| Verantwortliche/-r |
Dr.-Ing. Norbert Oster Prof. Dr. Michael Philippsen |
|---|
| Zeitpunkt | Startdatum - Enddatum | Ausfalltermin | Durchführende/-r | Bemerkung | Raum |
|---|---|---|---|---|---|
| nach Vereinbarung - | - |
|
2023
- , , , , :
Practical Flaky Test Prediction using Common Code Evolution and Test History Data
16th IEEE International Conference on Software Testing, Verification and Validation, ICST 2023 (Dublin, 16.04.2023 - 20.04.2023)
In: IEEE (ed.): Proceedings - 2023 IEEE 16th International Conference on Software Testing, Verification and Validation, ICST 2023 2023
DOI: 10.1109/ICST57152.2023.00028
BibTeX: Download - , , , , :
Practical Flaky Test Prediction using Common Code Evolution and Test History Data [replication package]
figshare (2023)
DOI: 10.6084/m9.figshare.21363075
BibTeX: Download
(online publication)
2020
- , , :
MutantDistiller: Using Symbolic Execution for Automatic Detection of Equivalent Mutants and Generation of Mutant Killing Tests
15th International Workshop on Mutation Analysis (Mutation 2020) (Porto, 24.10.2020 - 24.10.2020)
In: 2020 IEEE International Conference on Software Testing, Verification and Validation Workshops (ICSTW) 2020
DOI: 10.1109/ICSTW50294.2020.00055
URL: https://mutation-workshop.github.io/2020/
BibTeX: Download
2017
- , , :
AuDoscore: Automatic Grading of Java or Scala Homework
Third Workshop "Automatische Bewertung von Programmieraufgaben" (ABP 2017) (Potsdam, 05.10.2017 - 06.10.2017)
In: Sven Strickroth Oliver Müller Michael Striewe (ed.): Proceedings of the Third Workshop "Automatische Bewertung von Programmieraufgaben" (ABP 2017) 2017
Open Access: http://ceur-ws.org/Vol-2015/ABP2017_paper_01.pdf
URL: http://ceur-ws.org/Vol-2015/ABP2017_paper_01.pdf
BibTeX: Download
2011
- , :
Structural Equivalence Partition and Boundary Testing
Software Engineering 2011 - Fachtagung des GI-Fachbereichs Softwaretechnik (Karlsruhe, 24.02.2011 - 25.02.2011)
In: Ralf Reussner, Matthias Grund, Andreas Oberweis, Walter Tichy (ed.): Lecture Notes in Informatics (LNI), P-183, Bonn: 2011
URL: https://cs2-gitlab.cs.fau.de/i2public/publications/-/blob/master/SE2011-OsterPhilippsen-SEBT.pdf
BibTeX: Download
2008
- , , , :
Automatische Generierung optimaler modellbasierter Regressionstests
Workshop on Model-Based Testing (MoTes 2008) (München, 08.09.2008 - 13.09.2008)
In: Heinz-Gerd Hegering, Axel Lehmann, Hans Jürgen Ohlbach, Christian Scheideler (ed.): INFORMATIK 2008 - Beherrschbare Systeme dank Informatik (Band 1), Bonn: 2008
BibTeX: Download - , , :
Techniques and Tools for the Automatic Generation of Optimal Test Data at Code, Model and Interface Level
30th International Conference on Software Engineering (ICSE 2008) (Leipzig, 10.05.2008 - 18.05.2008)
In: Companion of the 30th international conference on Software engineering (ICSE Companion '08), New York, NY, USA: 2008
DOI: 10.1145/1370175.1370191
URL: http://dl.acm.org/ft_gateway.cfm?id=1370191
BibTeX: Download - , , :
Automatic Generation of Optimized Integration Test Data by Genetic Algorithms
Software Engineering 2008 - Workshop "Testmethoden für Software - Von der Forschung in die Praxis" (München, 19.02.2008 - 19.02.2008)
In: Walid Maalej, Bernd Bruegge (ed.): Software Engineering 2008 - Workshopband, Bonn: 2008
URL: http://www11.informatik.uni-erlangen.de/Forschung/Publikationen/TESO%202008.pdf
BibTeX: Download - , , :
White and Grey-Box Verification and Validation Approaches for Safety- and Security-Critical Software Systems
In: Information Security Technical Report 13 (2008), p. 10-16
ISSN: 1363-4127
DOI: 10.1016/j.istr.2008.03.002
URL: http://www.sciencedirect.com/science/article/pii/S1363412708000071
BibTeX: Download - , , :
Qualität und Zuverlässigkeit im Software Engineering
In: Zeitschrift für wirtschaftlichen Fabrikbetrieb 103 (2008), p. 407-412
ISSN: 0932-0482
URL: http://www.zwf-online.de/ZW101296
BibTeX: Download
2007
- :
Automatische Generierung optimaler struktureller Testdaten für objekt-orientierte Software mittels multi-objektiver Metaheuristiken (Dissertation, 2007)
URL: https://www.ps.tf.fau.de/files/2020/04/norbertoster_dissertation2007.pdf
BibTeX: Download - , :
Automatische Testdatengenerierung mittels multi-objektiver Optimierung
Software Engineering 2007 (Hamburg, 27.03.2007 - 30.03.2007)
In: Wolf-Gideon Bleek, Henning Schwentner, Heinz Züllighoven (ed.): Software Engineering 2007 - Beiträge zu den Workshops, Bonn: 2007
URL: http://subs.emis.de/LNI/Proceedings/Proceedings106/gi-proc-106-007.pdf
BibTeX: Download - , , , :
Automatische, modellbasierte Testdatengenerierung durch Einsatz evolutionärer Verfahren
Informatik 2007 - 37. Jahrestagung der Gesellschaft für Informatik e.V. (GI) (Bremen, 24.09.2007 - 27.09.2007)
In: Rainer Koschke, Otthein Herzog, Karl H Rödiger, Marc Ronthaler (ed.): Informatik 2007 - Informatik trifft Logistik, Bonn: 2007
URL: http://cs.emis.de/LNI/Proceedings/Proceedings110/gi-proc-110-067.pdf
BibTeX: Download - , :
Computer Safety, Reliability, and Security
Berlin Heidelberg: Springer-Verlag, 2007
(Lecture Notes in Computer Science, Vol.4680)
ISBN: 978-3-540-75100-7
DOI: 10.1007/978-3-540-75101-4
URL: http://link.springer.com/content/pdf/10.1007%2F978-3-540-75101-4.pdf
BibTeX: Download - , , :
Interface Coverage Criteria Supporting Model-Based Integration Testing
20th International Conference on Architecture of Computing Systems (ARCS 2007) (Zürich, 12.03.2007 - 15.03.2007)
In: Marco Platzner, Karl E Grosspietsch, Christian Hochberger, Andreas Koch (ed.): Proceedings of the 20th International Conference on Architecture of Computing Systems (ARCS 2007), Zürich: 2007
BibTeX: Download
2006
- , :
Automatic Test Data Generation by Multi-Objective Optimisation
25th International Conference on Computer Safety, Reliability and Security (SAFECOMP 2006) (Gdansk, 26.09.2006 - 29.09.2006)
In: Janusz Górski (ed.): Computer Safety, Reliability, and Security, Berlin Heidelberg: 2006
DOI: 10.1007/11875567_32
URL: http://link.springer.com/content/pdf/10.1007%2F11875567.pdf
BibTeX: Download
2005
- :
Automated Generation and Evaluation of Dataflow-Based Test Data for Object-Oriented Software
Second International Workshop on Software Quality (SOQUA 2005) (Erfurt, 20.09.2005 - 22.09.2005)
In: Ralf Reussner, Johannes Mayer, Judith A. Stafford, Sven Overhage, Steffen Becker, Patrick J. Schroeder (ed.): Quality of Software Architectures and Software Quality: First International Conference on the Quality of Software Architectures, QoSA 2005, and Second International Workshop on Software Quality, SOQUA 2005, Berlin Heidelberg: 2005
DOI: 10.1007/11558569_16
URL: http://link.springer.com/content/pdf/10.1007%2F11558569.pdf
BibTeX: Download
2004
- :
Automatische Generierung optimaler datenflussorientierter Testdaten mittels evolutionärer Verfahren
21. Treffen der Fachgruppe TAV [Test, Analyse und Verifikation von Software] (Berlin, 17.06.2004 - 18.06.2004)
In: Udo Kelter (ed.): Softwaretechnik-Trends 2004
URL: http://pi.informatik.uni-siegen.de/stt/24_3/01_Fachgruppenberichte/TAV/TAV21P4Oster.pdf
BibTeX: Download - , :
A Data Flow Approach to Testing Object-Oriented Java-Programs
Probabilistic Safety Assessment and Management (PSAM7 - ESREL'04) (Berlin, 14.06.2004 - 18.06.2004)
In: Cornelia Spitzer, Ulrich Schmocker, Vinh N. Dang (ed.): Probabilistic Safety Assessment and Managment, London: 2004
DOI: 10.1007/978-0-85729-410-4_180
URL: http://link.springer.com/chapter/10.1007%2F978-0-85729-410-4_180
BibTeX: Download
2002
- , , :
A Hybrid Genetic Algorithm for School Timetabling
AI2002 15th Australian Joint Conference on Artificial Intelligence (Canberra, 02.12.2002 - 06.12.2002)
In: Mc Kay B., Slaney J. (ed.): AI 2002: Advances in Artificial Intelligence - 15th Australian Joint Conference on Artificial Intelligence, Berlin Heidelberg: 2002
DOI: 10.1007/3-540-36187-1_40
URL: https://cs2-gitlab.cs.fau.de/i2public/publications/-/blob/master/AI02.ps.gz
BibTeX: Download
2001
- :
Implementierung eines evolutionären Verfahrens zur Risikoabschätzung (Diploma thesis, 2001)
BibTeX: Download - :
Stundenplanerstellung für Schulen mit Evolutionären Verfahren (Mid-study thesis, 2001)
BibTeX: Download
| 2025 | Mitglied der Berufungskommission W3-Professur Datenmanagement |
| 2010-2019 | embedded world Conference, PC-Mitglied, Session-Chair |
| 2016-2019 | MINTerAKTIV/GIFzuMINTS, Co-Projektkoordinator |
| 2015 | Software Engineering 2015 (SE2015), PC-Mitglied |
| 2012-2014 | WEMUCS - Methoden und Werkzeuge zur iterativen Entwicklung und Optimierung von Software für eingebettete Multicore-Systeme, Co-Projektkoordinator |
| 2012/2013 | Mitglied der Berufungskommission W2-Professur Didaktik der Informatik (Nachfolge Brinda) |
| 2006-2008 | UnITeD - Unterstützung Inkrementeller TestDaten, Co-Projektkoordinator |
| 2007 | International Conference on Computer Safety, Reliability and Security (SAFECOMP 2007), Mitglied des Organisationskommitees |
Unsere Examensarbeiten werden in StudOn verwaltet.
Bitte verwenden Sie die verfügbaren Filter, um nach bestimmten Einträgen zu suchen.
Kurzbeschreibung:
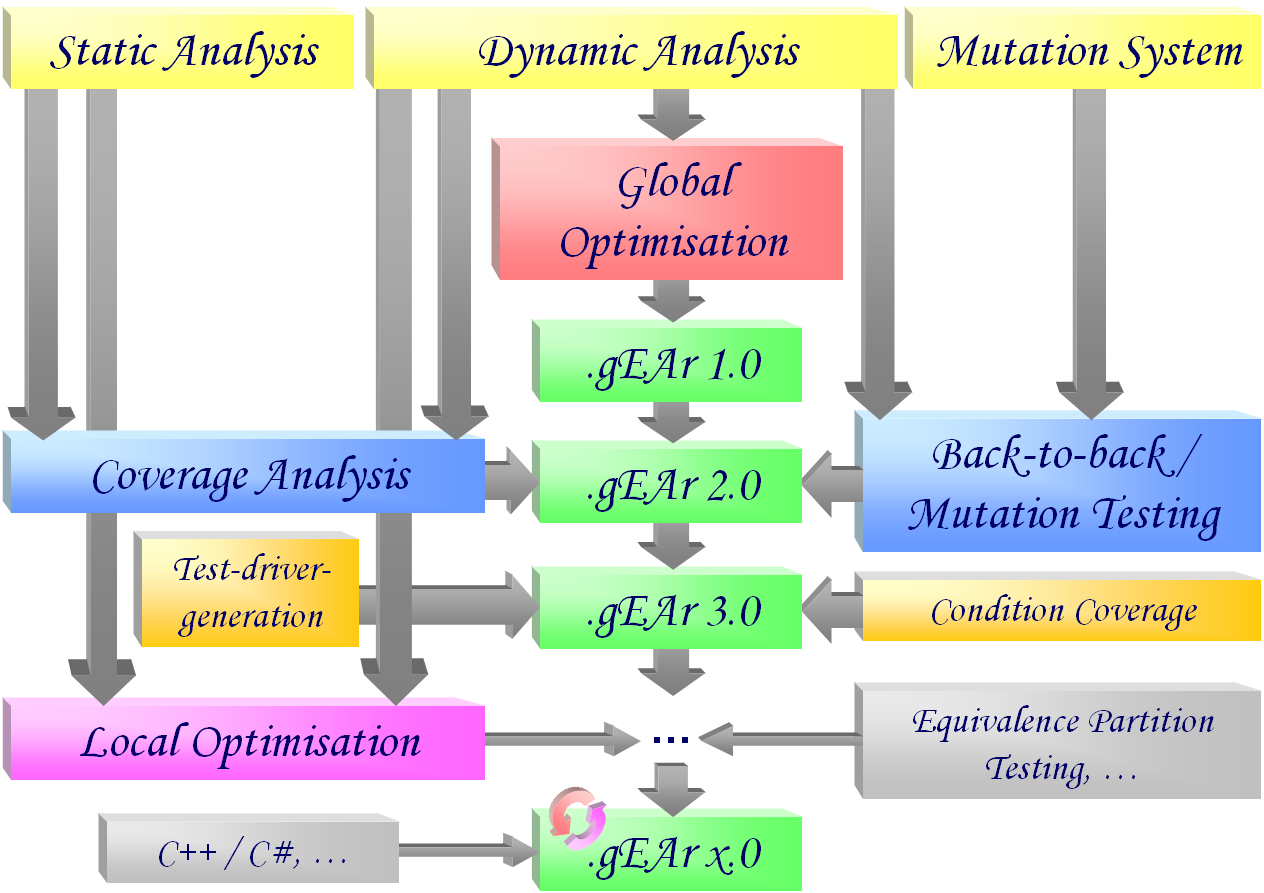
Die Zunahme der Komplexität moderner Softwaresysteme stellt trotz deutlich verbesserter Entwicklungsmethoden heute noch das Haupthindernis auf dem Weg zur fehlerfreien Programmerstellung dar. Größe und Budget heutiger Projekte verbieten meist eine vollständige formale Verifikation, die selbst in realisierbaren Fällen nur die logische Domäne der Programme und nicht ihr reales Umfeld einbezieht, weshalb dem Testen als Qualitätssicherungsmaßnahme vor der Freigabe der Software ein hoher Stellenwert eingeräumt wird. Um die Chancen der Fehlererkennung während der Testphase zu erhöhen, werden Testfälle nach unterschiedlichen Strategien ausgewählt: Während funktionales Testen die Eingaben aus den spezifizierten Anforderungen herleitet, streben strukturelle Tests eine möglichst vollständige Ausführung des Codes an. Bedingt durch die Komplexität der Kontrollstrukturen ist die Ermittlung geeigneter Testdaten zur Erfüllung datenflussorientierter Überdeckungskriterien besonders zeitaufwändig. Selbst wenn Testdaten zufällig generiert werden, müssen sie darüber hinaus meist manuell auf Korrektheit überprüft werden, so dass ihre Anzahl entscheidend zu Buche schlägt.
Ziel des laufenden Projekts ist es, die Generierung adäquater Mengen datenflussorientierter Testfälle zu automatisieren und unterschiedliche Verfahren hinsichtlich ihrer Eignung nach verschiedenen Kriterien (Güte, Aufwand) zu untersuchen. Als geeignete Such- und Optimierungsalgorithmen haben sich Evolutionäre Verfahren in unterschiedlichen Anwendungen erwiesen. Bisherige Arbeiten empfehlen bereits Genetische Algorithmen, jedoch wurde ihre Anwendbarkeit lediglich auf einfache Kontrollflusskriterien (etwa nach erzielten Anweisungs- oder Verzweigungsüberdeckungsmaßen) untersucht. Auch hat man bisher entweder eigene Programmiersprachen definiert oder bestehende soweit eingeschränkt, dass die Verfahren nicht mehr ohne weiteres auf reale Projekte übertragbar sind.
Erreichte Meilensteine
- Dynamische Analyse der Testausführung
Um die während der Ausführung eines Testfalls tatsächlich überdeckten Definitions- / Benutzungspaare (sogenannter def/use Paare) zu ermitteln, wurde ein Werkzeug zur Überwachung der dynamischen Ausführung eines Java-Programms entwickelt. Dieses Werkzeug instrumentiert den Quellcode des Testobjekts so, dass während eines einzelnen Testlaufs alle dazu relevanten Datenflussinformationen protokolliert werden. Die Ergebnisse wurden anlässlich der internationalen Tagung PSAM7/ESREL'04 publiziert. - Globale Optimierung von Testdatensätzen
Aufbauend auf der dynamischen Bewertung der von einem Testdatensatz erzielten Überdeckung wurde ein Verfahren entwickelt, um optimale Testdatensätze mittels klassischer und evolutionärer Suchstrategien zu generieren. Dabei werden Testdatensätze nach ihrem zu minimierenden Umfang sowie der zu maximierenden Anzahl der von ihnen überdeckten Datenflusspaare bewertet. Die erzielte globale Optimierung erfordert keine detaillierte Kenntnis der Kontrollflussstruktur des Testobjekts. Zur Generierung der Testdatensätze wurden unterschiedliche selbstadaptive Evolutionäre Verfahren sowie genetische Operatoren eingesetzt und vergleichend bewertet. Die verschiedenen Kombinationen wurden in einem parallelisierten, verteilten Werkzeug realisiert und getestet. Einzelheiten wurden von der GI-Fachgruppe TAV veröffentlicht. - Statische Analyse des Testobjekts
Zur Bewertung der relativen Güte der vom Evolutionären Verfahren ermittelten Ergebnisse wird zusätzlich zu den tatsächlich erreichten Überdeckungsmaßen (siehe dynamische Analyse) die Kenntnis der maximal erzielbaren Überdeckung benötigt, das heißt der Gesamtanzahl der von Tests auszuführenden Knoten, Kanten und Teilpfade des Kontrollflussgraphen. Zu diesem Zweck wurde ein statischer Analysator realisiert, welcher darüber hinaus auch die jeweiligen Definitionen und Benutzungen (sowie alle sie verbindenden DU-Teilpfade) jeder Variablen im datenflussannotierten Kontrollflussgraphen lokalisiert. Ergänzt um die Ergebnisse der dynamischen Analyse kann zum einen ein besseres Abbruchkriterium für die globale Optimierung definiert werden, zum anderen wird die im folgenden beschriebene lokale Optimierung unterstützt. - Bestimmung des Fehleraufdeckungspotentials der automatisch generierten Testfälle
Zusätzlich zur Bewertung der relativen Güte einer Testfallmenge im Sinne der Überdeckung (siehe statische Analyse) wurde im vorliegenden Projekt auch eine Schätzung der Qualität automatisch generierter Testfälle durch Betrachtung ihres Fehleraufdeckungspotentials angestrebt. Dazu wurde ein Back-to-back-Testverfahren nach dem Prinzip des Mutationstestens umgesetzt. Dabei werden repräsentative Fehler in das ursprüngliche Programm injiziert und das Verhalten der modifizierten Variante bei der Ausführung der generierten Testfälle mit dem der unveränderten Fassung verglichen. Der Anteil der verfälschten Programme, bei denen eine Abweichung im Verhalten aufgedeckt werden konnte, ist ein Indikator für das Fehleraufdeckungspotential der Testfallmenge. Die Ergebnisse der letzten beiden Teilaufgaben wurden anlässlich der internationalen Tagung SOQUA 2005 publiziert. - Ausdehnung des Ansatzes auf weitere Teststrategien
Das entwickelte Verfahren zur multi-objektiven Generierung und Optimierung von Testfällen lässt sich auch auf andere Teststrategien übertragen. Wählt man Überdeckungskriterien, welche zu den betrachteten datenflussorientierten Strategien orthogonal sind, ist die Erkennung anderer Fehlerarten zu erwarten. Im Rahmen eines Teilprojektes wurde beispielsweise ein Ansatz zur statischen Analyse des Testobjekts und dynamischen Analyse der Testausführung im Hinblick auf das Kriterium der Bedingungsüberdeckung entwickelt und implementiert. Ebenso wurde in einem weiteren Teilprojekt eine Unterstützung für das Kriterium der strukturellen Grenzwerttestüberdeckung umgesetzt, wodurch in Kombination mit den bestehenden Kriterien eine zusätzliche Erhöhung der Fehleraufdeckungsquote zu erwarten ist. - Ergänzung des Verfahrens um automatische Testtreibergeneratoren
Da für die automatische Generierung von Testfällen spezialisierte Testtreiber notwendig sind, welche sich nur bedingt zur manuellen Überprüfung der Testergebnisse eignen, wurde darüber hinaus im Rahmen eines Teilprojektes eine zweistufige automatische Testtreibergenerierung umgesetzt. Diese erstellt zunächst parametrisierbare Testtreiber, welche ausschließlich während der Testfalloptimierung eingesetzt werden, und übersetzt diese anschließend in die übliche jUnit-Syntax, sobald die generierten und optimierten Testdaten vorliegen. - Experimentelle Bewertung des entwickelten Werkzeugs
Die praktische Relevanz des entwickelten Verfahrens wurde in verschiedenen experimentellen Einsätzen erprobt und bewertet. Als Testobjekte dienten dabei Java-Packages mit bis zu 27 Klassen (5439 Codezeilen). Die nebenläufige Testausführung während der Generierung und Optimierung der Testfälle wurde auf bis zu 58 vernetzten Rechnern parallelisiert. Die Ergebnisse wurden anlässlich der internationalen Tagung SAFECOMP 2006 veröffentlicht.
Geplante Meilensteine
- Erweiterung des Leistungsumfangs der automatischen Generierung
Zusätzlich zu den bereits unterstützten Testkriterien aus der Familie der Kontroll- und Datenflussstrategien, wird die Methode und das umgesetzte Werkzeug auf weitere Testverfahren ausgedehnt. Auf der Basis der bereits entwickelten Verfahren und Werkzeuge, ist zu untersuchen, wie die obigen Forschungsergebnisse unter Einsatz von fach-spezifischem Wissen dahingehend erweitert und verbessert werden können, um die Heuristiken schneller und effizienter zu gestalten - beispielweise unter Einsatz verteilter Evolutionärer Verfahren. - Portierung des Werkzeugs zur Unterstützung weiterer Programmiersprachen
Nachdem die Implementierung der automatischen Erstellung von Testtreibern und der Generierung und Optimierung von Testdaten für Java-Programme bereits erfolgreich abgeschlossen wurde, ist die breitere Anwendbarkeit des Werkzeugs in der Industrie dadurch zu erreichen, dass die Unterstützung weiterer Programmiersprachen angeboten wird. Dazu gehört insbesondere die im eingebetteten Bereich verbreitete Familie der Sprache C - darunter die aktuelleren Derivate C++ und C#. Aufbauend auf den bisherigen Erkenntnissen für Java wird das bestehende Werkzeug um eine statische und eine dynamische Analyse für C#-Programme ergänzt. - Generierung zusätzlich erforderlicher Testdaten mittels lokaler Optimierung
Aus der bereits erfolgten Lokalisierung der Datenflusspaare (siehe statische Analyse) lassen sich insbesondere die für die Erfüllung des Testkriteriums fehlenden Testpfade ermitteln. Zugehörige Testfälle sollen durch die Anwendung Evolutionärer Verfahren in einer lokalen Optimierung generiert werden. Dazu wird eine neue Fitnessfunktion aufgrund graphentheoretischer Eigenschaften des Kontrollflussgraphen definiert. Die bereits umgesetzte Instrumentierung (dynamische Analyse) des Testobjekts wird passend erweitert. Somit wird die automatische Generierung der Testfälle gezielter lokal gelenkt und hinsichtlich Zeitaufwand und erzielter Datenflussabdeckung weiter verbessert.
- Download: Dissertation (PDF)