
Dr.-Ing. Norbert Oster
Research associates
Address
Contact
Ongoing Projects
Automatic grading of Java and Scala homework assignments
(Own Funds)Project leader: ,
Term: 18.07.2013 - 30.11.2028
Acronym: AuDoscore/ScExFuSS
URL: https://www.ps.tf.fau.de/forschung/forschungsprojekte/audoscore-scexfuss/Many students practice object-oriented or functional programming early on by independently implementing homework assignments. The huge number of participants and diverging approaches to solving problems make it difficult for lecturers to grade homework assignments (often exam requirements) according to a uniform standard.
That is why we developed an extension of JUnit in 2013 (at that time based on Java-1.7, JUnit-4, and Scala-2.12), the source code of which we publish at https://github.com/FAU-Inf2/AuDoscore (Java) and https://github.com/FAU-Inf2/ScExFuSS (Scala). Annotations assign test cases a bonus or penalty score. The results of the test execution are recorded and used to calculate a total score fully automatically. The evaluation is carried out in four stages, each of which provides detailed feedback immediately if necessary.
In 2025, we completely redesigned AuDoscore and ScExFuSS after key components became unusable due to the abrupt evolution of Java, JUnit, and Scala, which could no longer be kept running through constant adjustments. Since Java-25, the SecurityManager has been disabled as a security infrastructure. The severe restrictions imposed on the Java compiler API rendered it unusable for our purposes. Due to syntactic changes to the source and byte code, the previous pattern-based problem detection became non-deterministic. Newer JUnit versions have fundamentally different extension mechanisms (that are incompatible with the old ones).
Among others, this raised the following questions:
- How can we reliably prevent students from (un)intentionally disrupting the assessment system itself (previously through SecurityManager)?
- How can we detect when students use explicitly prohibited API functions (declared @Forbidden/@NotForbidden annotations)?
- How can we take into account in the assessment that students implement functions that build on each other incorrectly (consequential errors)?
- How can we integrate AuDoscore and ScExFuSS into the latest JUnit infrastructure?
To solve those problems in AuDoscore, we now use the "Classfile Package" from the Java-25 API. As a replacement for the SecurityManager and to implement the "@[Not]Forbidden" annotations, we use it to directly examine the bytecode for dangerous or prohibited function calls. To avoid consequential errors, we transplant classes, methods, or fields from the bytecode of the sample solution into the student's solution. This involves dealing with many difficult special cases (e.g. due to "type erasure", "lambdas", and many more), for which we may also transfer parts of the bytecode that are not directly in the code block of the method to be replaced and retranslate the tests appropriately for each test case.
To solve the above questions in ScExFuSS, we currently use the TASTy files (Typed Abstract Syntax Trees) generated by the compiler using the "Scala-3 Tasty Inspector". As a replacement for the SecurityManager and to handle the "@[Not]Forbidden" annotations, we statically check which functions are actually used. The consequential error handling based on the TASTy files is now also available for Scala for the first time.
For the purpose of migrating to JUnit-6, we ported AuDoscore, ScExFuSS, and all tests to JUnit-Jupiter. The "hooking" into the entire test execution process and the logging of evaluation events was implemented from scratch. As a result, we also updated all existing self-tests and added new ones to ensure that all changes and all new language features of Java-25, Scala-3, and JUnit-6 are handled correctly.
Completed Projects
Verification and validation in industrial practice
(Own Funds)Project leader:
Term: 01.01.2022 - 31.12.2024
Acronym: V&ViP
URL: https://www.ps.tf.fau.de/forschung/forschungsprojekte/vvip/Promote computer science as the basis for successful STEM studies along the entire education chain.
(Third Party Funds Single)Project leader: , ,
Term: 01.11.2019 - 31.10.2022
Acronym: CS4MINTS
Funding source: Bayerisches Staatsministerium für Wissenschaft und Kunst (StMWK) (seit 2018)
URL: https://www.ddi.tf.fau.de/forschung/laufende-projekte/cs4mints-informatik-als-grundlage-eines-erfolgreichen-mint-studiums-entlanComputer Science basics as an essential building block of modern STEM field curricula
(Third Party Funds Single)Project leader: , ,
Term: 01.10.2016 - 30.09.2019
Acronym: GIFzuMINTS
Funding source: Bayerisches Staatsministerium für Bildung und Kultus, Wissenschaft und Kunst (ab 10/2013)
URL: https://www.ps.tf.fau.de/forschung/forschungsprojekte/#gifzumintsTechniques and tools for iterative development and optimization of software for embedded multicore systems
(Third Party Funds Single)Project leader:
Term: 15.10.2012 - 30.11.2014
Acronym: WEMUCS
Funding source: Bayerisches Staatsministerium für Wirtschaft, Infrastruktur, Verkehr und Technologie (StMWIVT) (bis 09/2013)
URL: https://www.ps.tf.fau.de/forschung/forschungsprojekte/#wemucsInter-Thread Testing
(Own Funds)Project leader:
Term: 01.01.2012 - 31.12.2013
Acronym: InThreaTAutomatische Testdatengenerierung zur Unterstützung inkrementeller modell- und codebasierter Testprozesse für hochzuverlässige Softwaresysteme
(Third Party Funds Single)Project leader:
Term: 01.03.2006 - 31.10.2009
Acronym: UnITeD
Funding source: Bayerisches Staatsministerium für Wirtschaft, Infrastruktur, Verkehr und Technologie (StMWIVT) (bis 09/2013)
Testen von Softwaresystemen
Basic data
| Title | Testen von Softwaresystemen |
|---|---|
| Short text | TSWS |
| Module frequency | nur im Sommersemester |
| Semester hours per week | 4 |
Parallel groups / dates
1. Parallelgruppe
| Semester hours per week | 4 |
|---|---|
| Teaching language | Deutsch |
| Responsible |
Jonas Butz Dr.-Ing. Norbert Oster |
| Date and Time | Start date - End date | Cancellation date | Lecturer(s) | Comment | Room |
|---|---|---|---|---|---|
| wöchentlich Wed, 16:15 - 17:45 | 15.04.2026 - 15.07.2026 |
|
11301.00.005 | ||
| wöchentlich Thu, 16:15 - 17:45 | 16.04.2026 - 16.07.2026 | 04.06.2026 14.05.2026 |
|
12801.01.220 |
Intensivübungen zu Parallele und Funktionale Programmierung
Basic data
| Title | Intensivübungen zu Parallele und Funktionale Programmierung |
|---|---|
| Short text | PFP-IÜ |
| Module frequency | nur im Sommersemester |
| Semester hours per week | 2 |
Parallel groups / dates
1. Parallelgruppe
| Responsible |
Dr.-Ing. Norbert Oster Prof. Dr. Michael Philippsen David Schwarzbeck |
|---|
| Date and Time | Start date - End date | Cancellation date | Lecturer(s) | Comment | Room |
|---|---|---|---|---|---|
| wöchentlich Wed, 10:00 - 12:00 | 22.04.2026 - 15.07.2026 |
|
11901.U1.245 |
2023
- , , , , :
Practical Flaky Test Prediction using Common Code Evolution and Test History Data
16th IEEE International Conference on Software Testing, Verification and Validation, ICST 2023 (Dublin, 16.04.2023 - 20.04.2023)
In: IEEE (ed.): Proceedings - 2023 IEEE 16th International Conference on Software Testing, Verification and Validation, ICST 2023 2023
DOI: 10.1109/ICST57152.2023.00028
BibTeX: Download - , , , , :
Practical Flaky Test Prediction using Common Code Evolution and Test History Data [replication package]
figshare (2023)
DOI: 10.6084/m9.figshare.21363075
BibTeX: Download
(online publication)
2020
- , , :
MutantDistiller: Using Symbolic Execution for Automatic Detection of Equivalent Mutants and Generation of Mutant Killing Tests
15th International Workshop on Mutation Analysis (Mutation 2020) (Porto, 24.10.2020 - 24.10.2020)
In: 2020 IEEE International Conference on Software Testing, Verification and Validation Workshops (ICSTW) 2020
DOI: 10.1109/ICSTW50294.2020.00055
URL: https://mutation-workshop.github.io/2020/
BibTeX: Download
2017
- , , :
AuDoscore: Automatic Grading of Java or Scala Homework
Third Workshop "Automatische Bewertung von Programmieraufgaben" (ABP 2017) (Potsdam, 05.10.2017 - 06.10.2017)
In: Sven Strickroth Oliver Müller Michael Striewe (ed.): Proceedings of the Third Workshop "Automatische Bewertung von Programmieraufgaben" (ABP 2017) 2017
Open Access: http://ceur-ws.org/Vol-2015/ABP2017_paper_01.pdf
URL: http://ceur-ws.org/Vol-2015/ABP2017_paper_01.pdf
BibTeX: Download
2011
- , :
Structural Equivalence Partition and Boundary Testing
Software Engineering 2011 - Fachtagung des GI-Fachbereichs Softwaretechnik (Karlsruhe, 24.02.2011 - 25.02.2011)
In: Ralf Reussner, Matthias Grund, Andreas Oberweis, Walter Tichy (ed.): Lecture Notes in Informatics (LNI), P-183, Bonn: 2011
URL: https://cs2-gitlab.cs.fau.de/i2public/publications/-/blob/master/SE2011-OsterPhilippsen-SEBT.pdf
BibTeX: Download
2008
- , , , :
Automatische Generierung optimaler modellbasierter Regressionstests
Workshop on Model-Based Testing (MoTes 2008) (München, 08.09.2008 - 13.09.2008)
In: Heinz-Gerd Hegering, Axel Lehmann, Hans Jürgen Ohlbach, Christian Scheideler (ed.): INFORMATIK 2008 - Beherrschbare Systeme dank Informatik (Band 1), Bonn: 2008
BibTeX: Download - , , :
Techniques and Tools for the Automatic Generation of Optimal Test Data at Code, Model and Interface Level
30th International Conference on Software Engineering (ICSE 2008) (Leipzig, 10.05.2008 - 18.05.2008)
In: Companion of the 30th international conference on Software engineering (ICSE Companion '08), New York, NY, USA: 2008
DOI: 10.1145/1370175.1370191
URL: http://dl.acm.org/ft_gateway.cfm?id=1370191
BibTeX: Download - , , :
Automatic Generation of Optimized Integration Test Data by Genetic Algorithms
Software Engineering 2008 - Workshop "Testmethoden für Software - Von der Forschung in die Praxis" (München, 19.02.2008 - 19.02.2008)
In: Walid Maalej, Bernd Bruegge (ed.): Software Engineering 2008 - Workshopband, Bonn: 2008
URL: http://www11.informatik.uni-erlangen.de/Forschung/Publikationen/TESO%202008.pdf
BibTeX: Download - , , :
White and Grey-Box Verification and Validation Approaches for Safety- and Security-Critical Software Systems
In: Information Security Technical Report 13 (2008), p. 10-16
ISSN: 1363-4127
DOI: 10.1016/j.istr.2008.03.002
URL: http://www.sciencedirect.com/science/article/pii/S1363412708000071
BibTeX: Download - , , :
Qualität und Zuverlässigkeit im Software Engineering
In: Zeitschrift für wirtschaftlichen Fabrikbetrieb 103 (2008), p. 407-412
ISSN: 0932-0482
URL: http://www.zwf-online.de/ZW101296
BibTeX: Download
2007
- :
Automatische Generierung optimaler struktureller Testdaten für objekt-orientierte Software mittels multi-objektiver Metaheuristiken (Dissertation, 2007)
URL: https://www.ps.tf.fau.de/files/2020/04/norbertoster_dissertation2007.pdf
BibTeX: Download - , :
Automatische Testdatengenerierung mittels multi-objektiver Optimierung
Software Engineering 2007 (Hamburg, 27.03.2007 - 30.03.2007)
In: Wolf-Gideon Bleek, Henning Schwentner, Heinz Züllighoven (ed.): Software Engineering 2007 - Beiträge zu den Workshops, Bonn: 2007
URL: http://subs.emis.de/LNI/Proceedings/Proceedings106/gi-proc-106-007.pdf
BibTeX: Download - , , , :
Automatische, modellbasierte Testdatengenerierung durch Einsatz evolutionärer Verfahren
Informatik 2007 - 37. Jahrestagung der Gesellschaft für Informatik e.V. (GI) (Bremen, 24.09.2007 - 27.09.2007)
In: Rainer Koschke, Otthein Herzog, Karl H Rödiger, Marc Ronthaler (ed.): Informatik 2007 - Informatik trifft Logistik, Bonn: 2007
URL: http://cs.emis.de/LNI/Proceedings/Proceedings110/gi-proc-110-067.pdf
BibTeX: Download - , :
Computer Safety, Reliability, and Security
Berlin Heidelberg: Springer-Verlag, 2007
(Lecture Notes in Computer Science, Vol.4680)
ISBN: 978-3-540-75100-7
DOI: 10.1007/978-3-540-75101-4
URL: http://link.springer.com/content/pdf/10.1007%2F978-3-540-75101-4.pdf
BibTeX: Download - , , :
Interface Coverage Criteria Supporting Model-Based Integration Testing
20th International Conference on Architecture of Computing Systems (ARCS 2007) (Zürich, 12.03.2007 - 15.03.2007)
In: Marco Platzner, Karl E Grosspietsch, Christian Hochberger, Andreas Koch (ed.): Proceedings of the 20th International Conference on Architecture of Computing Systems (ARCS 2007), Zürich: 2007
BibTeX: Download
2006
- , :
Automatic Test Data Generation by Multi-Objective Optimisation
25th International Conference on Computer Safety, Reliability and Security (SAFECOMP 2006) (Gdansk, 26.09.2006 - 29.09.2006)
In: Janusz Górski (ed.): Computer Safety, Reliability, and Security, Berlin Heidelberg: 2006
DOI: 10.1007/11875567_32
URL: http://link.springer.com/content/pdf/10.1007%2F11875567.pdf
BibTeX: Download
2005
- :
Automated Generation and Evaluation of Dataflow-Based Test Data for Object-Oriented Software
Second International Workshop on Software Quality (SOQUA 2005) (Erfurt, 20.09.2005 - 22.09.2005)
In: Ralf Reussner, Johannes Mayer, Judith A. Stafford, Sven Overhage, Steffen Becker, Patrick J. Schroeder (ed.): Quality of Software Architectures and Software Quality: First International Conference on the Quality of Software Architectures, QoSA 2005, and Second International Workshop on Software Quality, SOQUA 2005, Berlin Heidelberg: 2005
DOI: 10.1007/11558569_16
URL: http://link.springer.com/content/pdf/10.1007%2F11558569.pdf
BibTeX: Download
2004
- :
Automatische Generierung optimaler datenflussorientierter Testdaten mittels evolutionärer Verfahren
21. Treffen der Fachgruppe TAV [Test, Analyse und Verifikation von Software] (Berlin, 17.06.2004 - 18.06.2004)
In: Udo Kelter (ed.): Softwaretechnik-Trends 2004
URL: http://pi.informatik.uni-siegen.de/stt/24_3/01_Fachgruppenberichte/TAV/TAV21P4Oster.pdf
BibTeX: Download - , :
A Data Flow Approach to Testing Object-Oriented Java-Programs
Probabilistic Safety Assessment and Management (PSAM7 - ESREL'04) (Berlin, 14.06.2004 - 18.06.2004)
In: Cornelia Spitzer, Ulrich Schmocker, Vinh N. Dang (ed.): Probabilistic Safety Assessment and Managment, London: 2004
DOI: 10.1007/978-0-85729-410-4_180
URL: http://link.springer.com/chapter/10.1007%2F978-0-85729-410-4_180
BibTeX: Download
2002
- , , :
A Hybrid Genetic Algorithm for School Timetabling
AI2002 15th Australian Joint Conference on Artificial Intelligence (Canberra, 02.12.2002 - 06.12.2002)
In: Mc Kay B., Slaney J. (ed.): AI 2002: Advances in Artificial Intelligence - 15th Australian Joint Conference on Artificial Intelligence, Berlin Heidelberg: 2002
DOI: 10.1007/3-540-36187-1_40
URL: https://cs2-gitlab.cs.fau.de/i2public/publications/-/blob/master/AI02.ps.gz
BibTeX: Download
2001
- :
Implementierung eines evolutionären Verfahrens zur Risikoabschätzung (Diploma thesis, 2001)
BibTeX: Download - :
Stundenplanerstellung für Schulen mit Evolutionären Verfahren (Mid-study thesis, 2001)
BibTeX: Download
| 2025 | Member of Berufungskommission W3-Professorship Data Management |
| 2010-2019 | embedded world Conference, PC-Member, Session-Chair |
| 2016-2019 | MINTerAKTIV/GIFzuMINTS, Project Coordinator |
| 2015 | Software Engineering 2015 (SE2015), PC-Member |
| 2012-2014 | WEMUCS - Methods and tools for iterative development and optimization of software for embedded multicore systems, Project Coordinator |
| 2012/2013 | Member of Berufungskommission W2-Professorship Didaktik der Informatik (Successor Brinda) |
| 2006-2008 | UnITeD - Unterstützung Inkrementeller TestDaten, Project Coordinator |
| 2007 | International Conference on Computer Safety, Reliability and Security (SAFECOMP 2007), Member of the Organizing Committee |
Our thesis are managed using StudOn.
Please use the available filters to search for specific entries.
Brief description:
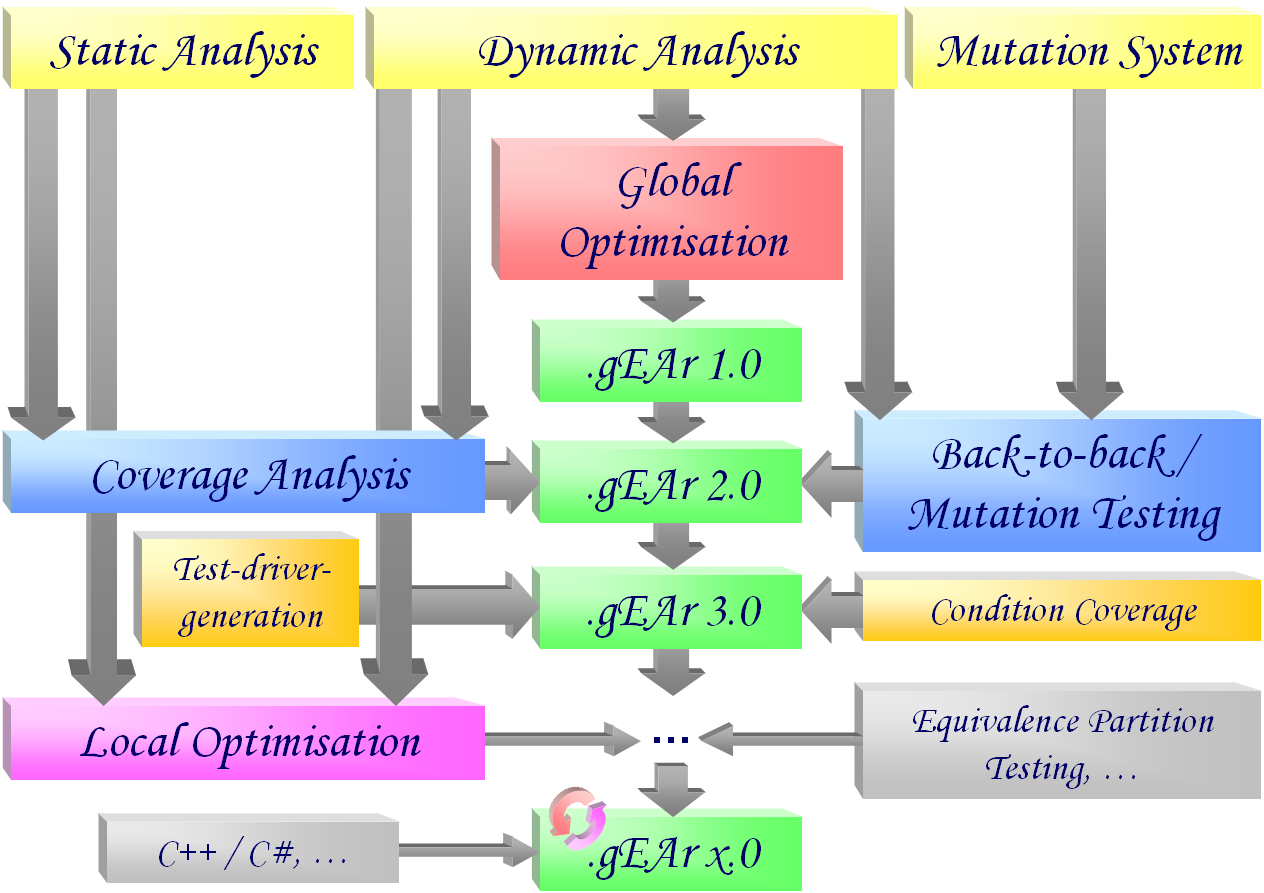
In spite of remarkably improved methods in software development, the increasing complexity of modern software systems still represents a main hindrance towards fault-free software development. Size and budget of today's projects mostly forbid a complete formal verification, which in turn covers only the logical domain of the code but not the real environment, even in cases where verification is feasible. On this account, testing is still considered to be an important means of quality assurance previous to the final release. In order to increase the chances of revealing faults during the testing phase, test cases are selected according to different strategies: for functional testing, inputs are derived from the specified requirements, whilst for structural testing the code has to be executed as exhaustively as possible. In consequence of the complexity of the control structures, the identification of test data allowing to achieve high dataflow coverage is exceedingly time consuming. Checking the correctness of the test results has usually to be carried out by hand and therefore requires a high amount of effort. Therefore, the overall number of test cases is crucial, even if their generation can be performed at low cost, e. g. by means of a random generator.
The aim of the ongoing research project is to automate the generation of adequate sets of dataflow-oriented test cases and to evaluate the adequacy of different techniques with respect to both quality achieved and effort required. In various application areas evolutionary algorithms have revealed as providing suitable search and optimisation strategies. Previous related investigations based on genetic algorithms were restricted to simple control flow criteria (statement and branch coverage), to special purpose programming languages or to language subsets hardly transferable to real projects.
Milestones achieved
- Dynamic analysis of the test execution
In order to identify the definition/use-pairs actually covered during the execution of a test case, a tool for monitoring the dynamic execution of a program was developed. It is intended to instrument the test object in such a manner that all relevant dataflow information is logged during each test run. The results were published on the occasion of the international conference PSAM7/ESREL'04. - Global optimization of test data sets
Based on the dynamic assessment of the coverage achieved by a test set, a procedure was developed aiming at generating an optimal set of test cases using evolutionary algorithms. The fitness function for evaluating each test set depends both on the number of covered dataflow pairs (see dynamic analysis) and on the size of the test set. For this reason the task is considered as a global optimisation problem independent from the control flow structure of the test object. For the actual generation of the test data, different genetic operators were developed to be used in parallel in the context of adaptive evolutionary algorithms. The different options were implemented in a toolset and tested and evaluated. Details have been published by the GI technical group TAV. - Static analysis of the test object
The evaluation of the results determined by the evolutionary algorithm requires the knowledge of both the coverage actually achieved (see dynamic analysis) and the coverage attainable. For this purpose a static analyzer has to locate the respective definitions and uses of each variable in the data flow graph. Together with the results achieved by the dynamic analysis, the static analysis is meant to improve the stopping criterion for the global optimisation. - Evaluation of the defect detection capability of the automatically generated test cases
In addition to evaluating the relative quality of a test set in terms of coverage (see static analysis), this project also aimed to estimate the quality of automatically generated test cases by considering their fault detection capability. For this purpose, a back-to-back test procedure based on the principle of mutation testing was implemented. Representative errors are injected into the original program and the behavior of the modified version during the execution of the generated test cases is compared with that of the unmodified version. The proportion of corrupted programs for which a deviation in behavior could be uncovered is an indicator of the fault detection capability of the test set. The results of the last two subtasks were published on the occasion of the international conference SOQUA 2005. - Extension of the approach to further testing strategies
The developed method for multi-objective generation and optimization of test cases can also be applied to other testing strategies. If coverage criteria are chosen which are orthogonal to the considered data flow oriented strategies, the detection of other types of defects can be expected. For example, in one subproject an approach for static analysis of the test object and dynamic analysis of the test execution with respect to the condition coverage criterion was developed and implemented. In another subproject, support for the structural equivalence class and boundary testing criterion was implemented, which, in combination with the existing criteria, is expected to result in an additional increase in the defect detection rate. - Addition of automatic test driver generators
Since specialized test drivers are required for the automatic generation of test cases, which are only suitable to a limited extent for the manual verification of test results, a two-stage automatic test driver generation was also implemented as part of a subproject. It first creates parameterizable test drivers, which are used solely during the test case optimization pahse, and then translates them into the usual jUnit syntax as soon as the generated and optimized test data is available. - Experimental evaluation of the developed tool
The practical relevance of the developed method was tested and evaluated in various experimental deployments. Java packages with up to 27 classes (5439 lines of code) served as test objects. The concurrent test execution during the generation and optimization of the test cases was parallelized on up to 58 networked computers. The results were published on the occasion of the international conference SAFECOMP 2006.
Planned milestones
- Extension of the automatic generation
In addition to the already supported testing criteria from the family of control and data flow strategies, the method and the implemented tool will be extended to other test procedures. Based on the already developed methods and tools, it is to be investigated how the above research results can be extended and improved using domain-specific knowledge in order to make the heuristics faster and more efficient - for example using distributed evolutionary methods. - Porting the tool to support other programming languages
Having already successfully implemented the automatic generation of test drivers and the generation and optimization of test data for Java programs, the broader applicability of the tool in industrial settings can be achieved by offering support for additional programming languages. This includes, in particular, the C language family widely used in the embedded domain - including the more recent derivatives C++ and C#. Building on the previous findings for Java, the existing tool will be extended to include static and dynamic analysis for C# programs. - Generation of additionally required test data by means of local optimization
Based on the identification of all data flow pairs (see static analysis), additional but yet missed control flow paths required for the fulfillment of the testing criterion can be determined. Corresponding test cases can be generated by applying evolutionary methods in a local optimization. For this purpose, a new fitness function is defined based on graph-theoretic properties of the control flow graph. The already implemented instrumentation (dynamic analysis) of the test object will be extended suitably. Thus, the automatic generation of test cases is locally directed in a more targeted way and further improved with respect to time and achieved data flow coverage.
- Download: Dissertation (PDF)